Part 1:本地 AI 崛起與顯存(VRAM)之戰
隨著雲端 AI 服務的商業化收割——如各大廠商陸續縮減免費額度、導入額外計費的點數機制(AI Credits)或在付費方案中禁用頂級模型——將 AI 部署在**本地端(Local Deployment)**已不再只是極客的玩具,而是開發者與隱私倡議者守護「數位自主權」的終極避風港。
如果您擁有一張配備強大顯示晶片與海量顯存的顯示卡(例如擁有 24GB VRAM 的旗艦顯示卡),您就擁有了在本地端打造無限制、無審查、零延遲 AI 帝國的「實體通行證」。
本篇文章將為您深入剖析本地端運行的意義、為什麼顯存(VRAM)是本地 AI 的靈魂,以及目前 GitHub 上最火熱、值得立刻動手復活的本地 AI 項目。
💡 為什麼選擇「本地 AI」?本地部署的終極意義
相較於調用雲端 API(如 OpenAI、Claude、Gemini),在本地端執行開源模型具有三大不可替代的優勢:
- 絕對的隱私安全(Privacy & Security): 您的代碼、個人日誌、私密對話或商業機密,完全不需要上傳到任何外部伺服器。所有的推理計算都在您的主機內完成,從物理層面上隔絕了數據洩露的風險。
- 零 API 費用與無限制使用(Zero Marginal Cost): 您不再需要盯著 API Token 消耗表,也不用擔心高頻率 Debug 導致帳單暴增。只要主機插著電,您就可以無限次地生成代碼、生成圖像、或與大模型進行深度交談。
- 極致的自由度與無審查(Censorship-Free): 雲端模型設有極為嚴格的對齊護欄(Guardrails),經常拒絕回答稍具敏感性的技術問題或創意寫作。本地開源模型(如未經審查的 Uncensored 版本)能完全聽從您的命令,徹底解放開發與創作的自由。
🧠 為什麼顯存(VRAM)是本地 AI 的靈魂?
在本地跑 AI 時,許多人會誤以為處理器(CPU)或系統記憶體(System RAM)是最關鍵的指標。然而,顯示卡顯存(VRAM, Video RAM)才是決定您能跑什麼級別模型、跑得多快的黃金瓶頸。
1. 顯存容量決定了模型的「生死線」
大語言模型(LLM)或擴散模型(Diffusion Models)的參數必須完整載入到顯存中,GPU 才能進行高速矩陣運算。
- 如果顯存足夠,模型完全載入,您能獲得極快的生成速度(每秒數十個 Token)。
- 一旦顯存溢出(OOM, Out of Memory),系統就必須將部分參數擠回速度極慢的系統記憶體(RAM)中,此時生成速度會斷崖式下跌,甚至直接報錯崩潰。
2. 參數大小與量化(Quantization)的數學公式
以開源模型 Llama 3 或 Qwen 2.5 為例:
- 一個 7B (70億參數) 的模型,在未壓縮認 FP16 精度下需要約
7 * 2 = 14GB的顯存。 - 透過量化技術(將權重壓縮為 4-bit 或 8-bit,即 Q4/Q8),7B 模型在 Q8 下僅需約 8GB 顯存,在 Q4 下更只需約 5.5GB 顯存。
- 若要運行更聰明的 32B (320億參數) 或 70B (700億參數) 模型:
- 32B (Q4) 約需 20GB 顯存。
- 70B (Q4) 則需要至少 40GB 以上的顯存。
這就是為什麼 24GB 顯存(如 RTX 3090 / 4090 / 5090)被公認為本地 AI 的「黃金分水嶺」——它剛好能在單卡上吃下 32B 量化模型或中等體積的混合專家模型(MoE),並為上下文緩存(KV Cache)留出足夠的空間。
🚀 盤點 GitHub 最火熱的本地 AI 項目
如果您擁有一台頂級硬體主機,以下這些 GitHub 開源項目是您絕對不容錯過的寶藏:
1. 後端推理與大模型引擎 (LLM)
- Ollama (GitHub Stars: 90k+)
- 簡介:本地大模型界的「Docker」。它將複雜的模型編譯、依賴與下載流程封裝成極簡的命令列工具。
- 體驗指令:只需在終端執行
ollama run qwen2.5:14b,就能立刻在本地開啟一個極為聰明的對話終端。
- llama.cpp
- 簡介:使用純 C/C++ 重寫的 Llama 推理後端,支持極致的硬體優化與混合推理(CPU + GPU),是幾乎所有本地大模型客戶端的底層引擎。
![]() 圖:本地大語言模型引擎 Ollama 官方標誌
圖:本地大語言模型引擎 Ollama 官方標誌
2. 本地圖像生成:ComfyUI 搭配 Civitai 生圖生態系
- ComfyUI (GitHub Stars: 50k+)
- 簡介:目前本地圖像生成最核心的節點流(Node-Based)推理引擎,支援 Stable Diffusion 與最新的 Flux 模型。
- 優勢:擁有極為精細的顯存調度管理。不同於傳統 WebUI,ComfyUI 的節點式架構能精確控制每一個推理步驟,即使在顯存受限的顯示卡上,也能藉由切分權重加載(Model Tiling/VRAM Swap)在本地流暢運行參數龐大的 Flux.1 與 SDXL 模型,生成細節極其精緻的二次元或寫實大圖。
- Civitai 資源庫與模型生態
- 簡介:本地 AI 生圖愛好者的「靈魂補給站」,也是全世界最大的開源 AI 藝術模型與工作流分享平台。
- 玩法:在 Civitai 上,您可以下載到各類經過微調的 LoRA 模型(如特定二次元角色、美術風格、光影控制)、精煉後的 Checkpoint 大模型,甚至可以直接下載其他分享的
.json格式 ComfyUI 工作流。直接將 Civitai 的工作流拖入 ComfyUI,就能在本地一鍵復現各種複雜的圖像生成與影像重繪任務。
3. 二次元互動桌寵 (AI Desktop Pets) & 虛擬主播
- Open-LLM-VTuber
- 簡介:目前開源界最完善的本地語音互動 Live2D AI 伴侶項目。
- 玩法:您的二次元桌寵擁有獨立的記憶庫(透過本地向量資料庫),她能聽懂您的語音輸入,並透過 GPT-SoVITS 語音庫以極為自然、帶有情感的日語或中文聲線回答您,同時做出眨眼、微笑等動態反饋,甚至還能透過鏡頭「看見」您。這一切,全部在本地端顯卡上運作。
- GPT-SoVITS (GitHub Stars: 35k+)
- 簡介:最強大的少樣本語音克隆工具。只需提供某個角色(如經典動漫角色或特定聲優)的一分鐘語音樣本,就能在本地訓練出專屬的語音合成模型,為您的本地桌寵注入靈魂。
 圖:Open-LLM-VTuber 結合本地大語言模型與語音合成的二次元互動 Live2D 桌寵官方橫幅
圖:Open-LLM-VTuber 結合本地大語言模型與語音合成的二次元互動 Live2D 桌寵官方橫幅
Part 2:🎨 實戰指南:Civitai 配合 ComfyUI 跑通第一個工作流
剛接觸 ComfyUI 那複雜的網格與連線可能會讓人望而生畏。但實際上,「Civitai + ComfyUI」 的搭配能讓你繞過繁瑣的搭建過程,快速上手。以下是獲取你第一個模型與工作流的保姆級步驟:
1. 準備你的第一個 Checkpoint 主模型
主模型(Checkpoint)是生成圖片的根基,決定了圖片是二次元動漫風格還是寫實照片風格。
- 進入 Civitai,點擊頂部的 Models 分類。
- 尋找標記為 Checkpoint 類型的熱門模型(例如適合動漫風的 Pony Diffusion 或適合寫實風的 Juggernaut)。
- 點擊 Download 下載模型檔案(通常是數 GB 的
.safetensors格式)。 - 將下載好的模型檔案,移入你的 ComfyUI 安裝目錄:
ComfyUI/models/checkpoints/檔案夾中。
2. 在 Civitai 尋找並下載工作流(Workflow)
ComfyUI 的強大之處在於圖片就是工作流的載體。Civitai 上的每張圖片,幾乎都隱藏著作者的節點工作流!
- 在 Civitai 上瀏覽,找到一張你非常喜歡、生成效果驚艷的圖片。
- 點擊圖片進入詳情頁,查看右側的元數據面板(Generation Data)。
- 如果右側顯示有 ComfyUI 圖示,直接點擊下載按鈕中的 Download Metadata(或是直接下載該圖片本身,因為 ComfyUI 的工作流數據會直接寫入 PNG 的元數據中)。
- 你也可以在 Civitai 的 Articles 或專門的工作流板塊直接下載
.json格式的工作流描述檔。
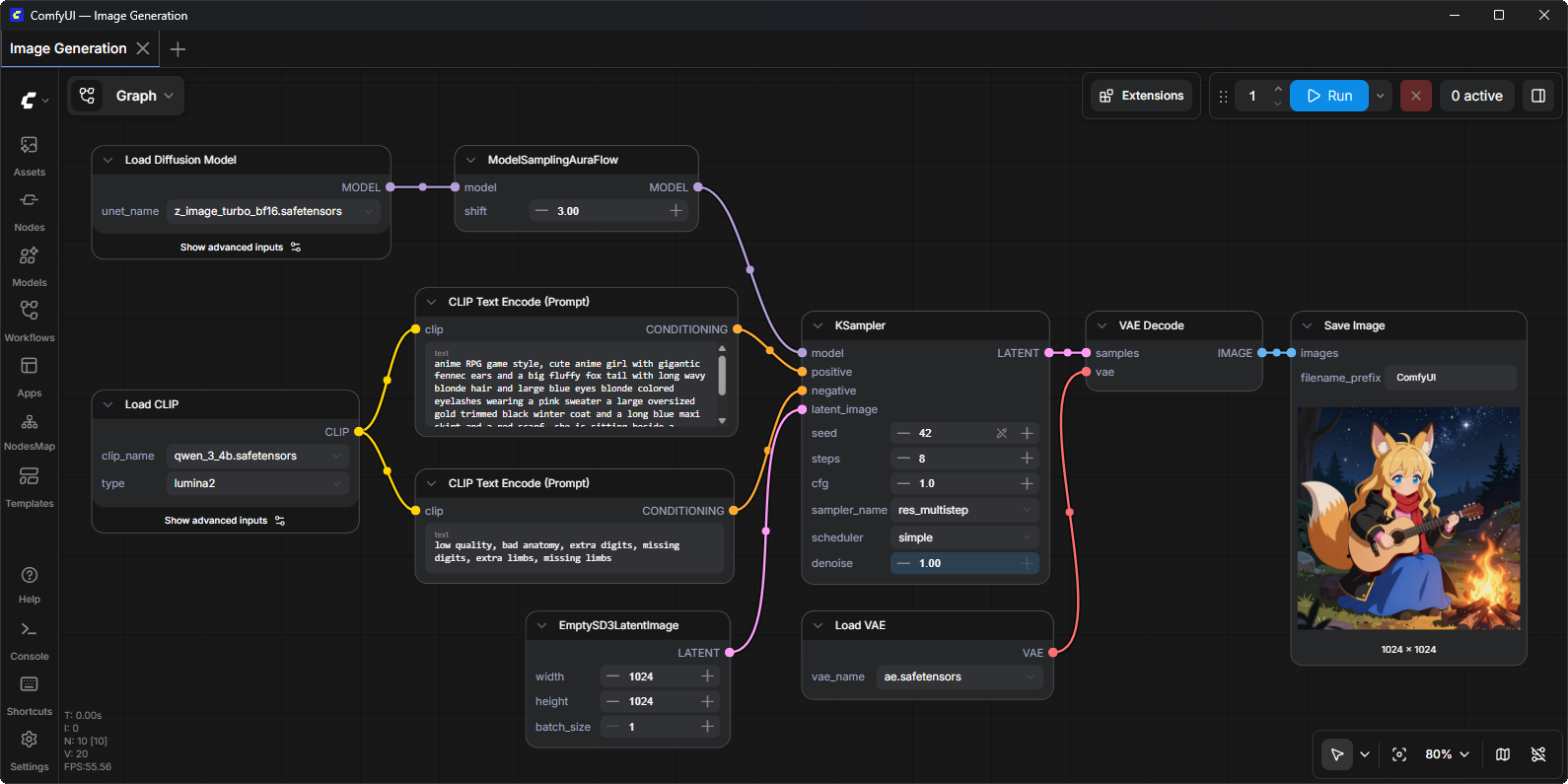 圖:ComfyUI 典型的節點式工作流操作介面
圖:ComfyUI 典型的節點式工作流操作介面
3. 載入 ComfyUI 並補齊缺失節點
- 啟動你的本地 ComfyUI,打開瀏覽器介面。
- 直接將下載的 JSON 工作流檔案(或者那張下載的 PNG 圖片)拖拽進 ComfyUI 瀏覽器視窗中。
- 此時,畫面上會自動還原作者的所有節點連線。
- 補齊紅色缺失節點:如果畫面上出現紅色的錯誤節點,說明你的本地環境缺少這些自訂擴充插件。
- 點擊 ComfyUI 右側懸浮控制面板的 Manager 進入管理介面:
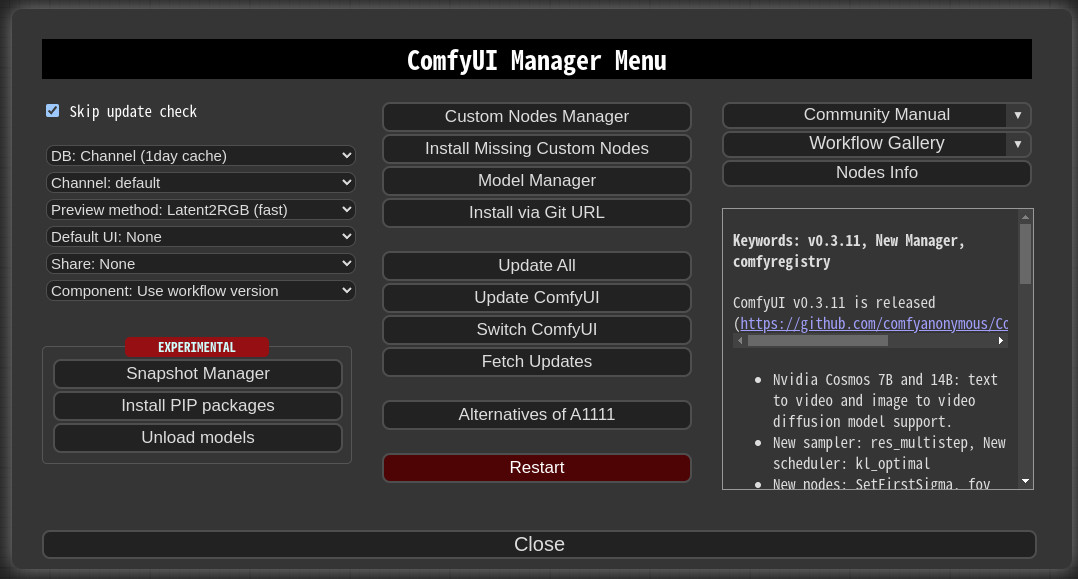
- 點擊 Install Missing Custom Nodes。
- Manager 會自動掃描當前工作流,列出所有紅色的缺失插件,勾選並點擊一鍵安裝。
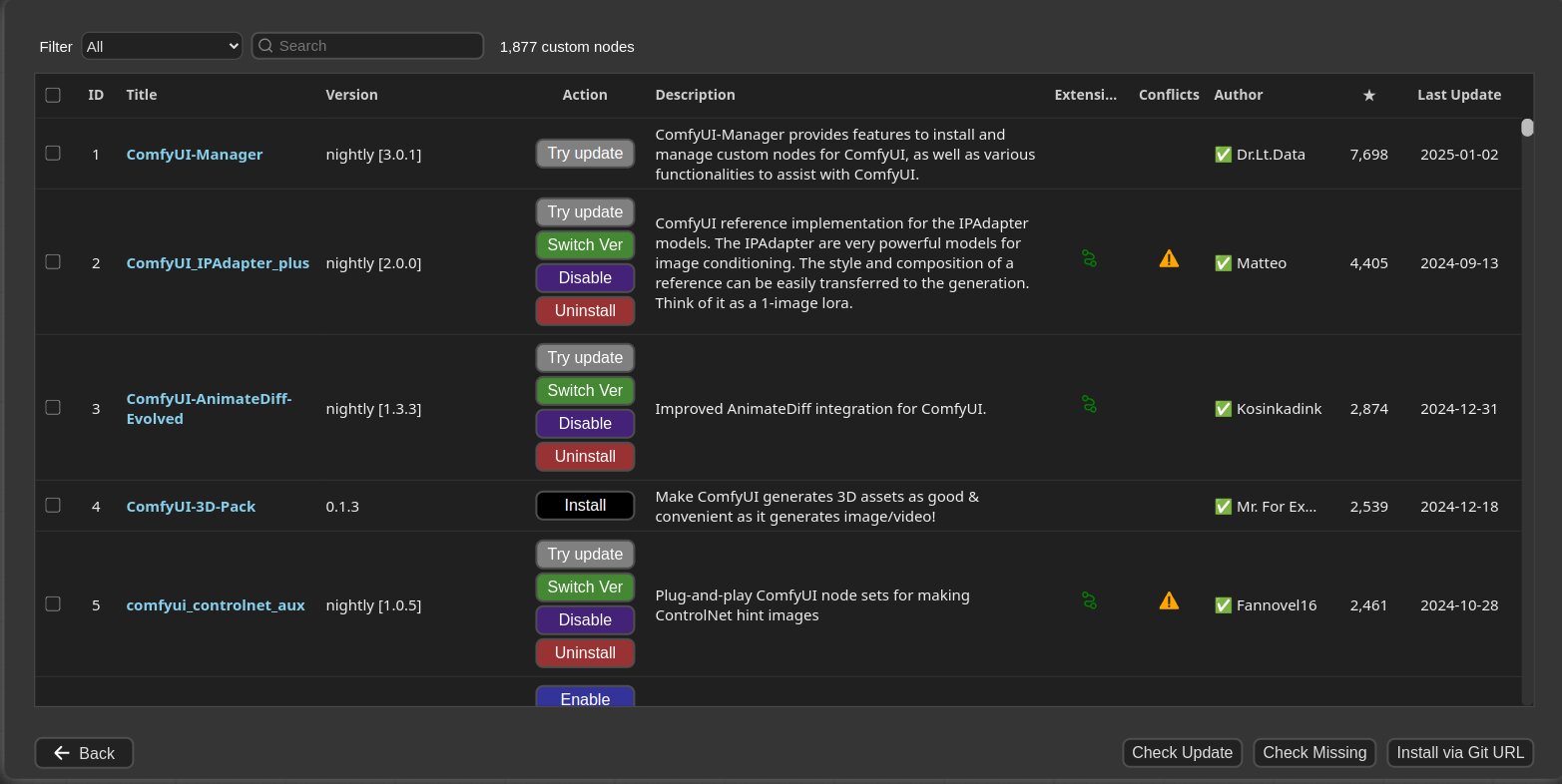
- 安裝完成後,重啟你的 ComfyUI 後端程式,重新整理網頁,紅色的缺失節點就會全部恢復正常!
- 點擊 ComfyUI 右側懸浮控制面板的 Manager 進入管理介面:
4. 放入 LoRA 與 Prompt,一鍵生成你的第一張畫作
- 在 Load Checkpoint 節點中,選擇你剛剛下載並放入資料夾的
.safetensors主模型。 - 如果工作流中包含 LoRA 節點,你需要去 Civitai 下載對應的 LoRA 檔案(例如特定服飾或人物模型),並放入
ComfyUI/models/loras/。 - 在兩個綠色的 CLIP Text Encode (Prompt) 節點中,分別輸入你想生成的畫面描述(正面提示詞)與不想看見的畫面(負面提示詞)。
- 點擊右側面板的 Queue Prompt 或是快捷鍵
Ctrl + Enter。 - 看著顯存被載入、節點一個個亮起綠框。數秒後,你的第一張高品質本地 AI 畫作就會在 Save Image 節點中完美誕生!
💡 結語:掌控您的數位生產力
本地 AI 的魅力在於**「掌控權」**。當我們不再依賴雲端主機的訂閱限制,當我們能在本地利用充足的顯存流暢地運行 ComfyUI 生圖、執行專屬的語音桌寵,並讓本地 LLM 後端協助日常編碼時,桌上這台由矽基晶片組成的怪獸主機才真正成為了個人意志の延伸。
對於擁有旗艦級硬體設備的開發者與創作者而言,本地部署是釋放開源 AI 潛能的必經之路。讓我們一起在本地環境中,把這些開源的矽基力量一一喚醒,體驗極致的數位自主權。
🔗 參考文獻與插圖來源
本篇文章內引用的各開源專案與示意插圖來源均整理於此,歡迎前往其官方儲存庫與社群進行探索與安裝:
- Ollama 大語言模型引擎:Ollama 官方 GitHub 專案
- ComfyUI 工作流推理介面:ComfyUI 官方 GitHub 專案
- Civitai AI 藝術模型社群:Civitai 官方網站
- ComfyUI-Manager 插件面板:ComfyUI-Manager 官方 GitHub 專案 及 ComfyUI-extension-tutorials
- Open-LLM-VTuber 二次元桌寵:Open-LLM-VTuber 官方 GitHub 專案
- GPT-SoVITS 少樣本語音克隆:GPT-SoVITS 官方 GitHub 專案
發表於本地技術日誌
評論功能尚未開放
RSS / 網站地圖
由 Astro 和 Fuwari 強力驅動
本站程式碼 已在 GitHub 存檔 (c8ab4b7 @ 2026-06-28 07:16:18)
本站立足於台灣,為全球華人提供服務